生成AIの仕組みを図解!中小企業が知るべき基礎知識
「ChatGPTって、どうやって文章を作っているの?」 そんな疑問を感じたことはありませんか?
生成AIは、大量のデータからパターンを学び、「次に来る言葉」を予測することで文章・画像・音声を作り出しています。仕組みを知ると、AIがぐっと身近に感じられます。
この記事では、生成AIの種類・構造・学習・生成のプロセスを、図解を交えてわかりやすく解説します。「AIをビジネスに活かしたい」とお考えの経営者・担当者の方に、ぜひ読んでいただきたい内容です。
Ⅰ. 生成AIの種類
生成AIは、「何を作るか(アウトプット)」 と 「どんな技術を使うか(モデル)」、用途別の技術の視点で整理できます。
1.作るものによる分類
| 種類 | できること | 代表サービス |
|---|---|---|
| テキスト生成 | 文章作成・翻訳・要約・コード記述 | ChatGPT / Gemini / Claude |
| 画像生成 | 文章の指示から画像を生成 | Midjourney / DALL·E 3 / Stable Diffusion |
| 動画生成 | 文章・静止画から動画を生成 | Sora / Runway / Luma Dream Machine |
| 音声・音楽生成 | 作曲・ナレーション・歌唱 | Suno / Udio / ElevenLabs |
2.技術(モデル)による分類
トランスフォーマー(Transformer) テキスト生成AIの心臓部です。文脈を理解し、次に来る確率の高い言葉を予測します。(例:ChatGPT)
拡散モデル(Diffusion Model) 画像生成で主流の技術です。砂嵐のようなノイズから、少しずつ形を作り出します。(例:Stable Diffusion)
GAN(敵対的生成ネットワーク) 「作る担当」と「見破る担当」の2つのAIを競わせ、本物そっくりの画像を生成します。
VAE(変分自己符号化器) データを圧縮・再構成することで、新しいバリエーションを生み出す手法です。画像加工や異常検知に活用されます。
3.用途別の技術
| 用途 | 技術 |
|---|---|
| 言語・会話・コード生成 | Transformer / LLM |
| 画像生成 | 拡散モデル(Diffusion) |
| 音声生成 | Waveモデル / 音響生成ネットワーク |
| 動画生成 | 時系列拡散モデル |
Ⅱ. 生成AIの構造
生成AIは、大量のデータから統計的パターンを学習し、確率予測によって新しいコンテンツを生成する技術です。
1.生成AIの全体アーキテクチャ
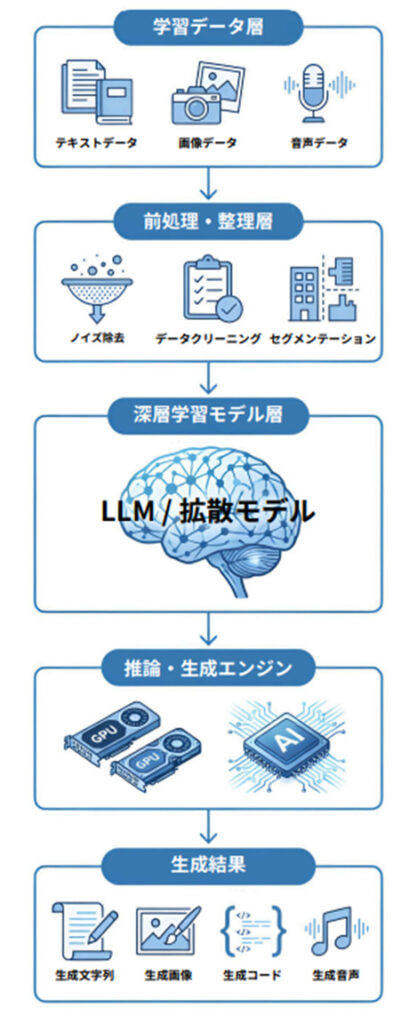
① 学習データ層 AIの「ガソリン」にあたる部分です。質の悪いデータを除く「データクリーニング」が、AIの精度を左右する重要な工程です。
② 前処理・整理層 AIが理解しやすい形式にデータを整えます。「アノテーション(意味付け)」や「正規化」といった処理が行われます。
③ 深層学習モデル層 データ間の「重み(つながりの強さ)」を学習する、AIの脳にあたる部分です。翻訳・画像生成など、あらゆるタスクに対応できる「汎用的な知能(基盤モデル)」が構築されます。
④ 推論・生成エンジン ユーザーの入力に対してミリ秒単位で確率計算を実行し、最適な答えを導き出す、予測と選択の心臓部です。
⑤ 生成結果 同じ「意味」というデータが、指示に応じてテキスト・画像・コードなど様々な形で出力されます。これを「マルチモーダル」と呼びます。
Ⅲ. 学習フェーズ:モデルの構築

1. データの数値化[1]
AIは文字や画像をそのままでは理解できません。まず言葉を「トークン(最小単位)」に分割し、数値に変換します。
「私はサッカーが好きです。」 →「私」「は」「サッカー」「が」「好き」「です」「。」
次に、各トークンを「ベクトル(数値の座標)」に変換します。これにより、「好き」と「大好き」は近い位置に、「好き」と「嫌い」は遠い位置に配置されます。AIは言葉の意味の近さを、数学的に計算できるようになります。
(1)トークン化する
最初に、LLMでは入力されたテキストデータを単語・記号・句読点といった、テキストの中で意味を持つ最小単位の要素(トークン)に分割していきます。たとえば、「私はサッカーが好きです。」という文があった場合、「私」「は」「サッカー」「が」「好き」「です」「。」といった具合に分割されます。この処理をトークン化といい、LLMが自然言語を理解し、処理するために非常に重要なステップです。
また、言語によってトークン化の処理は異なります。英語のような単語と単語の間にスペースが存在する言語はシンプルに分割できますが、日本語のように明確なスペースが存在しない言語ではトークン化のプロセスはより複雑になります。
(2)ベクトル化する
コンピューターはテキストデータをそのまま理解できないため、前のステップでトークン化されたテキストデータをベクトル(数値データ)に変換する必要があります。ベクトル化することでテキストが数値に変換され、コンピューターがテキストデータを認識し、情報として解析することが可能です。
また、ベクトル化によって各単語の関係性や意味の類似性も計算できるようになり、同義語や関連性の高い単語はベクトル上で近い位置に表現されます。これにより、次のステップとなるニューラルネットワークによる学習の精度が向上し、より自然な文章生成へとつながります。
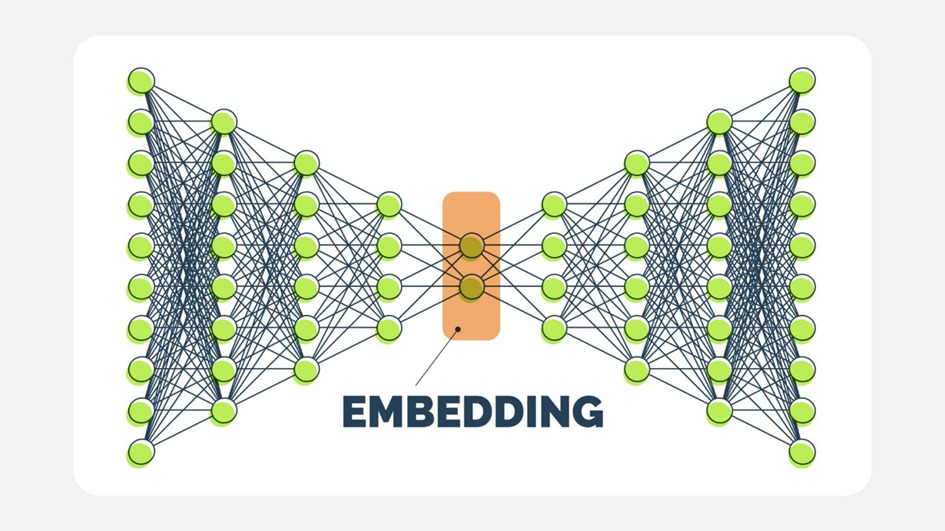
Embedding(エンベディング/埋め込み)とは、テキスト、画像、音声などのデータを、その意味や特徴を捉えた「数値の並び(高次元ベクトル)」に変換する技術です。似た意味を持つデータほどベクトル空間上で近い位置に配置されるため、AIや検索エンジンがデータの類似性を計算・分析するために利用されます。
データ → 分析 → ルール発見
AIは大量のデータを見て、
👉 言葉の並び方
👉 絵の特徴
👉 音の流れ
👉 何万冊も読書してクセを覚える状態です。
2. 2つのルール発見
① 教師あり学習(予測・分類) 正解データをもとに「こういう特徴ならこうなる」というルールを学びます。
例:気温・湿度・風速データ → 「雨が降る確率」を予測
② 教師なし学習(構造の発見) 正解なしで、データ同士の共通点を自動で見つけます。
例:購買履歴 → 「週末にビールとオムツを一緒に買う層がいる」という法則を発見
AIによる分析の強みは、100以上の要素が絡み合う複雑なルールも見つけられる「多変量分析」と、思い込みを排除した「客観性」にあります。
3. 深層学習(ディープラーニング)
ベクトル化されたテキストデータは、続いてニューラルネットワークに入力されます。ニューラルネットワークは、「入力層」「隠れ層(中間層)」「出力層」といった複数の層で構成されており、LLMの核となる部分です。隠れ層が多いほどより複雑なデータの解析が可能で、各層を通過するたびに異なる特徴を抽出しながらデータを処理していきます。
この過程を通してLLMは、単語の出現率、文法的な構造、単語間の関係性などを学習していきます。これら学習によって、LLMはテキストデータの細かなニュアンスも理解できるようになり、より自然かつ精度の高い自然言語処理を実現できます。
【大量データを入力】
↓
【ニューラルネットで予測】
↓
【正解とのズレを計測】
↓
【パラメータ(調整ネジ)を微修正】
↓
※ これを何万回も繰り返して「賢いモデル」が完成!
企業に例えると「ベテラン社員のノウハウを数値化して、全社員で共有できる状態」に近いイメージです。
(1)予測を支える「微調整」の仕組み
①ニューラルネット(脳の配線)
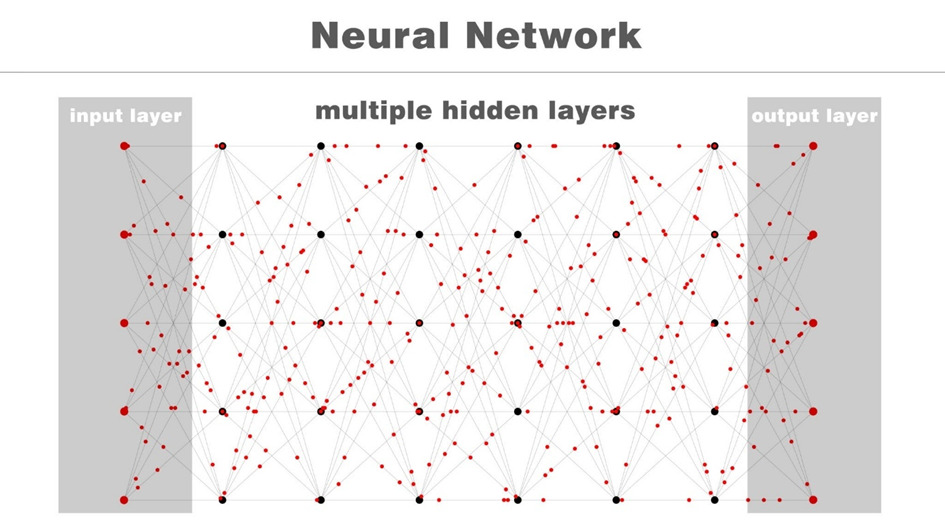
人間の脳細胞(ニューロン)を模した計算ユニットが、幾層にも重なっています。データはこの層を通り抜ける間に、計算・加工されていきます。
②パラメータ最適化(間違い探しと修正)
AIは最初、デタラメな予測をします。そこから「正解」とのズレを計算し、つまみを少しずつ回して精度を上げていきます。
- 順伝播:データを入力して予測してみる
- 誤差の計算:「正解は猫だけど、犬と予測した。ズレはこれくらいだ」と把握する
- 逆伝播(バックプロパゲーション):ズレを解消するように、パラメータ(調整ネジ)を少しずつ修正する
Ⅳ. 推論フェーズ:リアルタイム予測

1. 推論の処理フロー
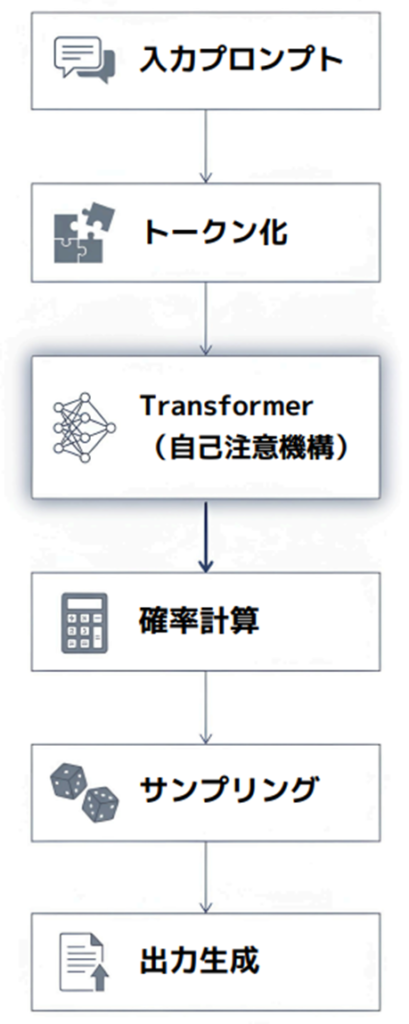
最大のポイントは 「Self-Attention(自己注意機構)」 です。
- 文全体の関係性を同時に見る
- 前後の意味を加味して予測する
- 長文でも整合性を保つ
これが従来AIとの大きな違いです。このフローはGoogleが発表した「Attention Is All You Need」以来、GPT-4・Gemini・Claudeなど現在の生成AIが例外なく採用しています。
(1)トークン化 言葉を意味の最小単位に分割し、ID番号に変換します。 「AIはすごい」→ [AI][は][すご][い] → [123][45][678][90]
(2)自己注意機構(Self-Attention) 文中の「どの言葉が、どの言葉と関係しているか」を計算します。 「彼はリンゴを食べて、それが甘いと言った」→ AIは「それ」が「リンゴ」を指すと理解します。
(3)確率分布計算 & サンプリング すべての単語候補に「次に来る確率」を割り振り、次のトークンを選びます。
2. Transformerの内部構造
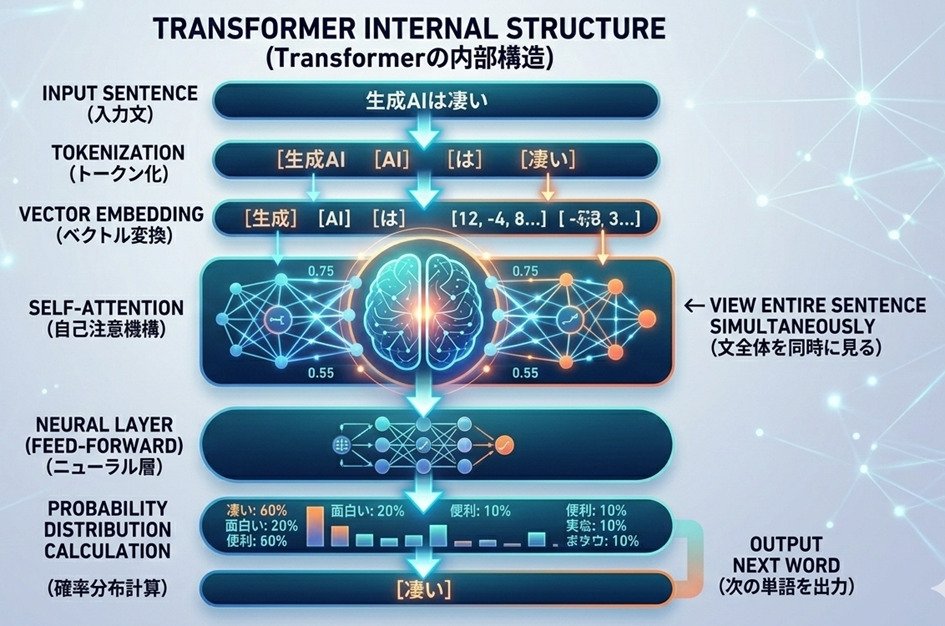
(1)ベクトル変換(埋め込み)
「トークン化」されたIDは、数千次元の空間上の「座標(ベクトル)」に変換されます。
- 「王」と「女王」
- 「東京」と「日本」 これらが空間上の近い位置に配置されることで、AIは言葉の「意味の近さ」を数学的に扱えるようになります。
(2)Self-Attention(関連性の計算)
「文全体を同時に見る」際、AIは単語同士に「スコア(重み)」を付けます。
「彼は(A)公園で(B)犬と(C)遊んだ」
- 「遊んだ」を処理するとき、AIは「誰が(A)」と「何と(C)」に高いスコアを振り、動作の主体と対象を特定します。
(3)ニューラル層(情報の統合)
Attentionで得られた「どの単語が重要か」という情報を、複雑な関数(FFN:フィードフォワードネットワーク)に通して、さらに深い概念へと昇華させます。
3. 自己注意機構のイメージ
「私は昨日、新しいPCを買った」という文では、AIはすべての単語を同時に関連付けて理解します。
| 注目する単語 | 強く注目する相手 | AIが理解していること |
|---|---|---|
| 買った | 私は | 誰が買ったか(主語) |
| 買った | 新しいPCを | 何を買ったか(目的語) |
| 新しい | PC | 何が新しいか(修飾関係) |
| 昨日 | 買った | いつ買ったか(時制) |
昔のAIは言葉を左から右へ順番に処理していたため、文の後半では前半の情報を「忘れがち」でした。TransformerはSelf-Attentionにより、文全体を一枚の絵のように眺めて理解できます。
Ⅴ. 生成フェーズ

1. 生成プロセスの流れ
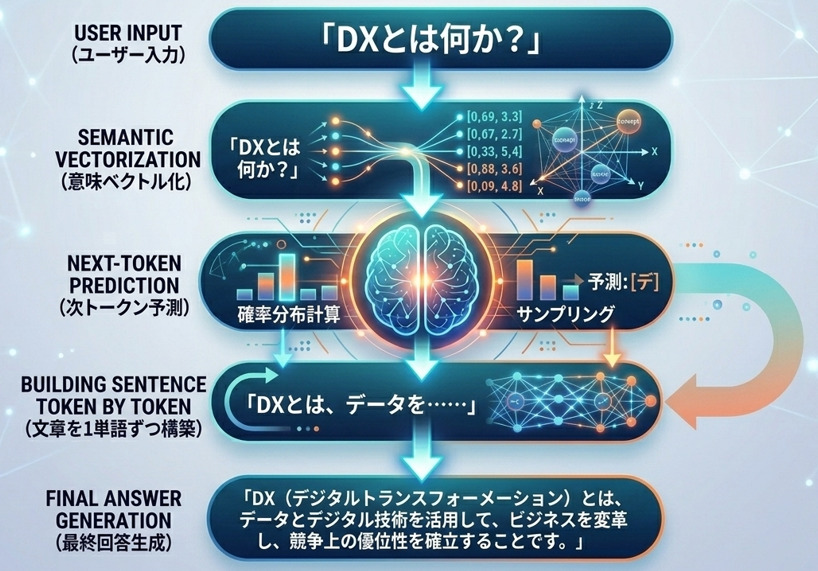
このプロセスの中で、AIが「意味」という抽象的な概念をどう扱っているかを少し補足すると、この図がさらに立体的になります。
(1)各ステップの「舞台裏」
①意味ベクトル化(エンコーディング)
「DXとは何か?」という文字は、AIの内部で数千次元の空間に浮かぶ「点(座標)」に変換されます。
AIはこの「点」の周りにある「デジタル変革」「IT活用」「ビジネスモデル」といった近接する概念を同時にスキャンしています。
②次トークン予測(生成の心臓部)
AIは一気に回答を作るのではなく、最初の「D」や「デ」を出すために、膨大な計算を行います。
前の単語とのつながりだけでなく、「ユーザーの質問(DXとは?)」という意図に常に立ち返りながら、次の1パーツを選びます。
③文章を1単語ずつ構築
ここで図の「ループ」が発生します。
1つ単語を出す → それを自分の入力に加える → また次の単語を予測する
この「自分の出した答えを自分で読み直す」繰り返しが、論理的な文章を作ります。
(2)「最終回答」ができるまでのイメージ
私たちがチャット画面で、文字が「パラパラパラ……」と出てくるのを見ることがありますよね。あれは演出ではなく、まさにAIが1トークンずつ予測し、構築しているリアルタイムの姿そのものです。
| プロセス | 状態 |
| 構築中 1 | 「DX(デジタルトランスフォーメーション)とは、」 |
| 構築中 2 | 「DXとは、データとデジタル技術を……」 |
| 構築中 3 | 「DXとは、データとデジタル技術を活用して、ビジネスを……」 |
2. 生成のしくみ(自己回帰)
この「予測の繰り返し」は専門用語で 「自己回帰(Autoregressive)」 と呼ばれます。
①文章:数珠つなぎの連鎖
一文字(または単語の断片)ずつ、前の文脈をすべて踏まえて「次」を足していきます。
- 予測1: 「吾輩(わがはい)」
- 予測2: 「は」
- 予測3: 「猫」
- 予測4: 「で」
- 予測5: 「ある」
- 結果: 一つの物語が完成
②画像:霧が晴れるような連鎖
画像AI(拡散モデルなど)の場合は、少し特殊です。最初はただの「砂嵐(ノイズ)」から始まり、何度も予測を繰り返して「ノイズを取り除いていく」ことで完成させます。
- 予測1: 「この砂嵐の中に、うっすら猫の輪郭がある気がする」
- 予測2: 「耳はこのあたりかな」
- 予測3: 「毛並みはこうかな」
- 予測4: 「背景は庭かな」
- 結果: 一枚の高精細な画像が完成
3. なぜ途中で支離滅裂にならないのか?
長い文章を生成しても一貫性が保たれるのは、次の仕組みのおかげです。
Attention(注目機能) 「最初に何を頼まれたか」や「重要なキーワード」を、文章が長くなっても忘れずに注目し続けます。一貫性の保持 直前の予測だけでなく、全体の構成を崩さないようにバランスを取り続けます。
まとめ
生成AIは「魔法」ではなく、「大量のデータ × 統計的な予測の積み重ね」 です。
- データからルールを学び
- Transformerで言葉の関係を計算し
- 1トークンずつ予測を繰り返して出力する
この仕組みを理解するだけで、AIツールの使い方が変わり、ビジネスへの活用アイデアも広がります。
「自社でも生成AIを導入してみたい」「何から始めればいいかわからない」という方は、ぜひお気軽にご相談ください。中小企業のDX推進を、一緒に考えます。

